
General transcription is the conversion of audio or video recordings into written text for business use, not a biology concept like “general transcription factors.” It covers meetings, interviews, training sessions, webinars, and research recordings without requiring specialist subject knowledge.
Modern organisations generate continuous spoken content that remains unused until transcribed into searchable, shareable, and actionable text.
This guide explains what general transcription includes, when to use it, how output formats differ, and when to upgrade to specialised or multilingual transcription workflows.
What General Transcription Covers: Content Types, Output Formats, and the Three Accuracy Tiers
General transcription covers diverse business audio types, but every project requires defined formats and accuracy levels to ensure usability, compliance, and downstream application efficiency.
General Transcription Content Types
| Content Type | Typical Source Format | Common Business Purpose | Typical Length | Speaker Count | Key Accuracy Requirement |
| Business meetings (internal) | Zoom/Teams/Google Meet; in-room recording | Action tracking; decision records | 30–90 minutes | 2–10 | Speaker identification; clear actions |
| Job interviews and HR recordings | Audio/video interviews | Compliance; candidate evaluation | 30–60 minutes | 2–3 | Exact responses; no paraphrasing |
| Qualitative research interviews | Remote or in-person recordings | Thematic analysis; insights | 45–90 minutes | 2 | Verbatim for coding accuracy |
| Focus groups | Multi-speaker recordings | Consumer insight; product research | 60–120 minutes | 6–12 | Speaker labelling; cross-talk handling |
| Webinars and online events | Video/live recordings | SEO; repurposing; accessibility | 30–90 minutes | 1–4 | Timestamps; technical accuracy |
| Training videos / eLearning | Pre-recorded video | Accessibility; knowledge base | 5–60 minutes | 1–2 | Subtitle-ready accuracy |
| Podcasts and audio content | MP3/WAV/M4A | SEO blogs; repurposing | 20–90 minutes | 1–4 | Natural readability; filler control |
| Conference presentations | Event/livestream recordings | Post-event content; quoting | 20–60 minutes | 1–5 | Accurate data/statistics |
| Dictation / voice memos | Mobile recordings | Notes; drafts; field input | 1–30 minutes | 1 | Clean read standard |
Verbatim, Clean Read, and Edited Transcription: Which Format Does Your Project Need?
Choosing verbatim, clean read, or edited transcription determines usability, legal reliability, and analytical value. Verbatim captures every spoken element, including filler words, pauses, repetitions, and overlaps. It is required for qualitative research, legal review, and HR investigations.
Clean read removes non-essential speech while preserving meaning, making it the default for meetings, webinars, and business documentation.
Edited transcription restructures content into publication-ready text with improved readability. Selecting the wrong tier creates operational risk because critical meaning is either lost or buried in noise.
Speaker Identification and Timestamping: When They Are Essential and How They Work
Speaker identification and timestamping are required for multi-speaker clarity, accountability, and navigation across long recordings.
Named, numbered, or role-based labels structure transcripts for meetings, research, and HR documentation.
Timestamping at 1–2 minute intervals or per speaker turn enables precise navigation for legal review, editing, and captioning workflows. Cross-talk handling using [OVERLAP] or [CROSSTALK] is critical in focus groups and panels where multiple speakers talk simultaneously.
What Affects Transcription Accuracy: Audio Quality, Accents, Technical Terms, and Background Noise
Transcription accuracy ranges from 70% to 99%+ depending on audio quality, speaker complexity, and terminology density. High-quality recordings with clear microphones deliver near-perfect accuracy.
Poor audio, overlapping speakers, strong accents, and technical vocabulary reduce accuracy significantly. Human transcription outperforms automated tools in complex scenarios.
Best practice includes using dedicated microphones, minimising noise, and recording at ≥128 kbps for reliable output quality.
General Transcription vs Specialised Transcription: How to Identify Which Type Your Project Needs
The difference between general and specialised transcription is defined by domain knowledge requirements, not complexity, specialist content demands subject expertise to ensure accuracy, compliance, and usability.
Transcription Type Comparison

| Transcription Type | Domain Knowledge Required | Typical Content | Key Accuracy Standard | Who Commissions It | When General Is Insufficient |
| General transcription | None — language fluency | Meetings, interviews, webinars, podcasts | Clean read or verbatim; general vocabulary accuracy | Business teams, content teams | When terminology errors or compliance risk appear |
| Legal transcription | Legal terminology, procedure | Depositions, hearings, HR investigations | Strict verbatim; court formatting | Law firms, legal teams | Any legal content requires specialist handling |
| Medical transcription | Medical terminology, anatomy | Clinical notes, consultations, trials | Verbatim with medical accuracy; GDPR/HIPAA | Healthcare, CROs | Any clinical or pharmacological content |
| Market research transcription | Research methodology | Focus groups, IDIs, UX sessions | Verbatim for coding; speaker labelling | Research agencies, insights teams | Any research requiring analysis or coding |
| Technical transcription | Engineering/scientific knowledge | R&D meetings, technical training | Terminology precision; spec accuracy | Engineering, product teams | Technical jargon or IP-sensitive content |
| Financial transcription | Financial terminology, regulation | Earnings calls, investor meetings | Accurate figures; often verbatim | Finance, compliance teams | Regulatory or investor-facing content |
Legal Transcription: Why Verbatim Accuracy and Formatting Standards Make It a Specialist Service
Legal transcription requires strict verbatim accuracy, legal formatting standards, and terminology precision to ensure admissibility and compliance.
Every spoken word forms part of the legal record, including pauses, corrections, and objections. Court formats such as Q&A deposition structure, exhibit references, and line numbering must be followed precisely.
Using general transcription introduces legal risk because terminology errors or formatting inconsistencies can invalidate documents or weaken evidentiary value in proceedings.
Market Research Transcription: Verbatim Standards, Coding Compatibility, and Focus Group Complexity
Market research transcription requires verbatim accuracy because qualitative analysis depends on exact wording, not cleaned summaries.
Filler words, pauses, and self-corrections carry analytical meaning in thematic coding. Focus groups with 6–12 participants introduce cross-talk and overlapping speech that automated tools cannot resolve accurately.
Cleaned or paraphrased transcripts destroy data integrity, making them unusable for coding frameworks such as grounded theory or discourse analysis.
When General Transcription Needs to Be Paired With Translation: Multilingual Transcription Workflows
Multilingual transcription requires integrated transcription and translation workflows to maintain accuracy across languages and use cases. Native-language transcription is required for non-English audio.
Transcription-then-translation ensures quality control for long or complex recordings. Subtitle workflows require timed formats such as SRT or VTT.
Direct audio translation skips transcription but reduces traceability. Combined workflows deliver source transcripts plus translated outputs for compliance, research, and global content distribution.
How to Brief a General Transcription Project: 5 Decisions That Determine Quality and Cost
Transcription quality, turnaround, and cost are determined before the project starts, clear briefing decisions eliminate rework, reduce risk, and control pricing.
Decision 1: Verbatim or Clean Read — and What to Do When You’re Unsure
Choose verbatim for legal, HR, or research use; choose clean read for business documentation and content reuse. Verbatim preserves every utterance.
Clean read removes noise while keeping meaning. Default to clean read when unsure, it is operationally usable. State downstream use clearly to confirm the correct format at briefing stage.
Decision 2: Speaker Identification Requirements and How to Provide Speaker Information
Multi-speaker recordings require defined speaker identification, named speakers for accountability, labelled speakers for speed.
Provide a speaker introduction at the start of the recording where each participant states name and role.
This creates a voice reference and improves identification accuracy, especially in 3–10 speaker meetings or interviews.
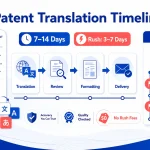
Decision 3: Turnaround Time, Rush Options, and Pricing Structure
Turnaround and pricing scale directly with urgency, audio complexity, and speaker count. Standard delivery requires 4–6 hours per audio hour. Rush delivery increases cost by 1.5× to 3× depending on speed.
| Delivery Speed | Turnaround | Pricing Multiplier | Best Use Case |
| Standard | 24–48 hours (≤90 mins audio) | 1× | Planned projects; research |
| Same-day | 6–12 hours (≤60 mins audio) | 1.5–2× | Urgent meetings |
| Express | 4 hours (≤30 mins audio) | 2–3× | Legal or critical decisions |
Pricing benchmarks: clean read £0.75–£1.50/min; verbatim £1.00–£1.75/min; complex multi-speaker £1.25–£2.00+/min. AI transcription costs £0.05–£0.15/min but introduces accuracy risk in complex scenarios.
Decision 4: Confidentiality Requirements and Data Handling for Sensitive Business Recordings
Confidential recordings require defined data handling, NDA protection, and GDPR-compliant processing before any file transfer.
HR, legal, financial, and research recordings contain sensitive data. Confirm NDA coverage, retention policy, and DPA compliance. Verify whether AI tools are used and how data is processed. Lack of clarity here creates compliance exposure.
Decision 5: File Delivery Format and Downstream Use Planning
Delivery format must match downstream use to avoid rework and formatting inefficiency. Define the end use before production begins.
| Downstream Use | Recommended Format | Key Reason |
| Internal meetings | Word (.docx) with timestamps | Editable, shareable |
| Legal/compliance | PDF + Word | Archival integrity + working file |
| Research coding | Word or .txt | Compatible with NVivo, MAXQDA |
| Subtitles/captions | SRT/VTT | Time-coded for video |
| Blog/content reuse | Word clean read | Ready for editing/publication |
| Training/LMS | Structured Word | Searchable, import-ready |
| Transcription + translation | Source + translated Word files | Consistency across languages |
Incorrect format selection creates operational delays because transcripts must be reformatted or reprocessed after delivery.
Commission General and Specialised Transcription — With Audio Translation When You Need It
Accurate, confidential transcription and audio translation delivered in the format your business actually uses — from meetings to research and multilingual content.
✓ Human transcription — native-language transcriptionists; no AI-only processing for confidential content
✓ Verbatim or clean read — defined at briefing; format locked before production
✓ Speaker identification — named or labelled; voice reference supported; focus group expertise (6–12 speakers)
✓ Timestamping — speaker change, per minute, or caption-ready (SRT/VTT)
✓ Multilingual transcription — 40+ languages; native-language accuracy for non-English audio
✓ Transcription + translation — source transcript and target-language output delivered together
✓ Legal and research standards — verbatim accuracy; coding-ready transcripts; court-ready formatting
✓ GDPR-compliant handling — DPA available; audio deleted within 30 days
✓ NDA before file transfer — mandatory for all projects
✓ Audio translation — direct or transcription+translation workflows based on use case
✓ Fast turnaround — same-day (≤60 minutes audio) or standard 24–48 hours
Tell us your audio length, speaker count, content type, format, and deadline — receive a precise quote within 1 business hour →
Get a Transcription Quote →
View Audio Translation Services →
View Translation and Localisation Services →
General Transcription — Frequently Asked Questions
What is the difference between general transcription and audio translation?
General transcription converts audio into text in the same language, while audio translation converts it into a different language. An English recording becomes an English transcript; a French recording becomes an English translated text. In multilingual workflows, transcription is completed first, then translation. Some workflows use direct audio translation, but this reduces traceability and auditability for regulated or research use.
How accurate is AI transcription compared to human transcription for business recordings?
AI transcription achieves 85–95% accuracy on clear audio, while human transcription achieves 98–99%+ accuracy. Accuracy drops to 70–80% for AI with multiple speakers, accents, or technical terminology. Human transcription maintains high accuracy across complex recordings. For HR, legal, research, or compliance content, human transcription is the required standard due to risk and data integrity requirements.
What is the difference between transcription and captions/subtitles?
Transcription produces a standalone text document, while captions and subtitles are timed text synced to video. Transcripts are delivered in formats such as Word or PDF for reading and reference. Captions use formats like SRT or VTT with timestamps. Professional workflows typically create a transcript first, then convert it into captions or subtitles for video use.
How long does it take to transcribe one hour of audio?
One hour of audio takes 4–6 hours to transcribe professionally, resulting in a 24-hour standard turnaround. Complex audio (multiple speakers, noise, technical content) increases this to 6–10 hours. AI-assisted transcription with human review reduces turnaround to 2–4 hours. Same-day delivery is typically available for recordings up to 60 minutes.
Can general transcription be used for research that will be published or submitted academically?
Clean-read general transcription is not suitable for academic research — verbatim transcription is required. Qualitative research depends on exact wording, including pauses, filler words, and overlaps. Cleaned transcripts remove analytical data and compromise validity. For research use, always specify verbatim transcription with full notation to meet publication and methodological standards.
What is the correct transcription format for subtitles and captions?
SRT and VTT are the required formats for subtitles and captions. These formats include timestamps for each text segment. Accessibility standards (WCAG 2.1, ADA) require captions to be accurate and synchronised within approximately 2 seconds of speech. Speaker identification is included where relevant. These formats are mandatory for video platforms and broadcast compliance.
Is transcription covered by GDPR when recordings contain personal data?
Yes, transcription is subject to GDPR when recordings contain personal data. The transcription provider acts as a data processor under GDPR Article 28. A Data Processing Agreement (DPA) is required before sharing files. This applies to employee recordings, research interviews, and customer calls containing identifiable information. Compliance must be confirmed before project start.
What is the difference between meeting minutes and a meeting transcript?
A transcript records everything said; minutes summarise decisions and actions. Transcripts include full speaker dialogue and discussion detail. Minutes extract key points, decisions, and action items in structured format. Transcripts serve as evidential records; minutes serve governance and operational needs. Many organisations require both for compliance and internal documentation.
Can Circle Translations transcribe non-English audio recordings?
Yes, native-language transcription is available in 40+ languages. Recordings are transcribed by native speakers of the source language, not via AI translation. Supported languages include European, Asian, and Middle Eastern languages such as French, German, Spanish, Arabic, Japanese, and Chinese. Multilingual recordings can be handled with combined transcription and translation workflows.